近期,MILab在可解释图像分类研究方面取得新进展,相关研究论文“V2C-CBM: Building Vision-to-Concept Tokenizer”已被AAAI 2025会议接收(poster),并受邀在第二届Imageomics研讨会(“Discovering Biological Knowledge from Images using AI”)做口头报告。
概念瓶颈模型(Concept Bottleneck Model,CBM)是一类自身可解释的分类模型,其通过首先训练概念预测器,将图像映射为一组可理解的概念,再将概念作为输入,训练概念到类别的分类器,实现自身可解释的图像分类。同时,用户也可以直接检查和修改模型的概念预测结果,通过介入的方式提升模型性能和理解模型决策。由于其自身可解释性和有竞争力的分类性能,概念瓶颈模型成为了目前可解释人工智能领域的热门研究方向。然而,概念瓶颈模型的训练需要大量的细粒度概念级标签,如CBM领域常用的测试基准CUB细粒度鸟类分类数据集,每张图像需要额外标注112个概念标签。这限制了概念瓶颈模型在大型数据集(如ImageNet)或需要专家知识的任务(如医学图像分析)上的应用。现有一些工作借助大语言模型来缓解这一问题,他们通过直接查询大语言模型(例如:“请你列举绿色蓝鸦的显著特征”),来获取一组概念,并利用CLIP等视觉-语言模型进行概念预测,以此来构建概念瓶颈模型。虽然这些方法成功将概念瓶颈模型扩展到如ImageNet等大型数据集中,但基于大语言模型的方法普遍存在两类问题:(1)大语言模型会生成一些非视觉概念,如“这种鸟类常见于欧洲”,从而降低了模型基于图像分类的可解释性与忠实性;(2)大语言模型容易生成过于冗杂的概念,而一句过长的描述中可能包含多个独立的概念、使得用户难以判断模型是否根据特定概念进行分类,也提高了用户检查概念预测结果和介入的难度。

在此背景下,MILab研究团队提出了一种不使用大语言模型,仅从视觉角度出发,既可以在无概念标签的情况下构建概念瓶颈模型的新方法——视觉-概念分词器(Vision-to-Concept Tokenizer,V2C Tokenizer),通过直接将视觉特征量化为文本概念,构建概念瓶颈模型。其中,原始的概念词汇表来自于日常使用中最常用的单个词汇(词频统计来自于Google);然后我们基于大量无标签图像、和目标任务的类别名称,基于CLIP获取到与该类别更相关的无标签图像,用于后续的视觉概念文本筛选。通过利用与目标任务更相关的无标签图像与视觉语言模型,我们根据CLIP特征空间中视觉特征-文本特征的相似度,对概念词汇表进行再一次的词频更新,从而获得我们与目标任务联系紧密的概念码表(concept codebook)。构建了codebook之后,V2C Tokenizer可以直接通过欧氏距离查找与输入图像视觉特征最接近的一组视觉概念文本特征,继而构建概念瓶颈模型(V2C-CBM)。
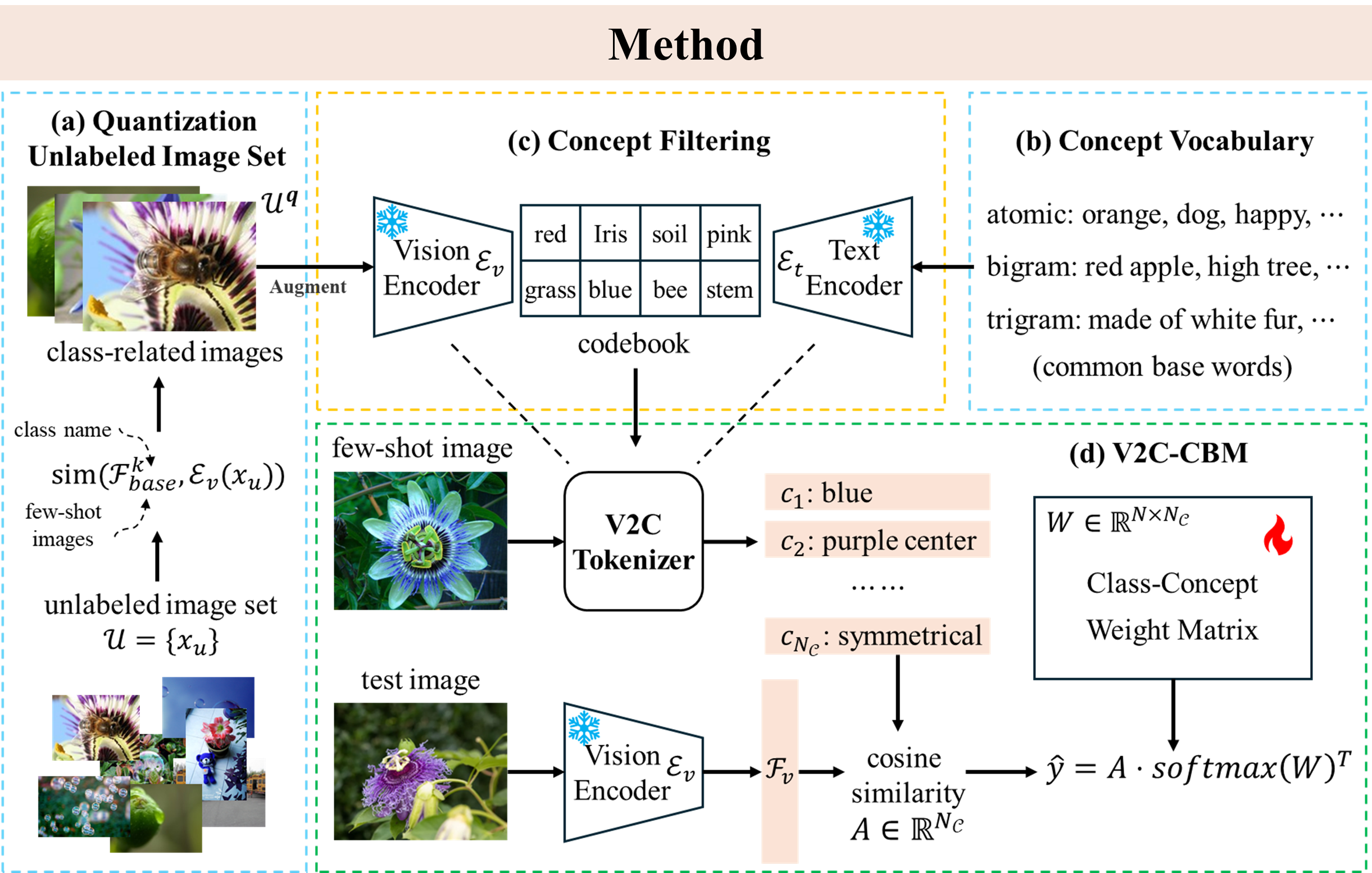
研究团队在多个数据集上进行实验,包括常用的分类基准CIFAR10/100、ImageNet,细粒度图像分类数据集CUB、Food-101、Flower-102、Aircraft,以及纹理图像分类数据集DTD、遥感图像分类数据集RESISC45和皮肤病图像分类数据集HAM10000,充分验证了方法的有效性。多项实验结果表明,本文构建的V2C Tokenizer可以有效发现各类别图像的显著视觉特征,并用于构建可解释且准确的概念瓶颈模型。
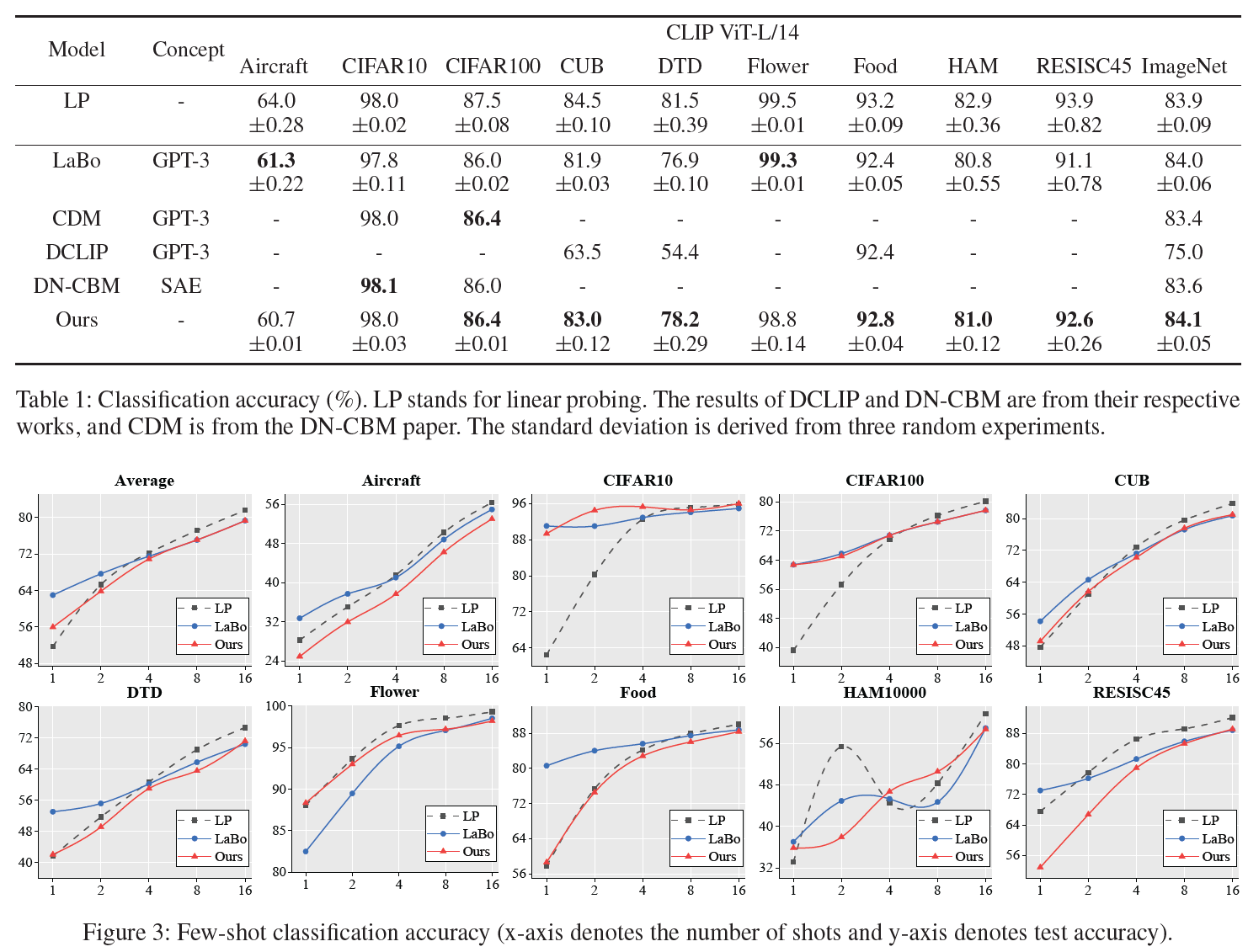
除了用于概念瓶颈模型实现可解释的图像分类之外,本方法还可以用于发现特定类别的显著视觉特征或影像知识,如细粒度的动物特征,日常物品特征等等。在第二届Imageomics研讨会上,V2C Tokenizer也额外吸引了来自动物学、生物学等领域的研究者,交流探讨了其在从图像中发现生物知识的应用前景。

该论文第一作者为MILab课题组博士生何航舟,卢闫晔助理教授为本文的通讯作者。其他合作者还包括MILab博士后朱磊、博士生张心亮、曾爽和陈倩。该研究得到了国家自然科学基金等项目的经费支持。
文章链接:[2501.04975] V2C-CBM: Building Concept Bottlenecks with Vision-to-Concept Tokenizer
0 评论