近期,MILab在理解生成统一模型上取得进展,验证了在3D理解生成统一模型中存在“生成促进理解”现象 ,相关研究论文“Omni-View: Unlocking How Generation Facilitates Understanding in Unified 3D Model based on Multiview images”已被ICLR 2026会议接收。这篇文章介绍并分析了“生成促进理解”在统一模型中存在,并基于此特性增强现有空间理解模型的性能。
该工作从分析空间理解任务所需的性质入手。现有的空间理解任务可以分为两大类:几何计算与时序推理。如下所示:

而这两种特性可通过自回归式视频生成与几何预测(或称为世界模型中的next state prediction范式)习得。我们探究并验证了这一范式的可行性,基于理解生成统一模型Bagel,我们提出Omni-View用以验证以上“生成促进理解”猜想。具体地,Omni-View的架构与训练方式如下:

Omni-View 由理解模型、纹理模块和几何模块组成,联合建模场景理解、新视角合成和几何估计,实现了三维场景理解和生成任务之间的协同交互。该模型巧妙地利用了纹理模块的时空建模能力(用于外观合成)以及专用几何模块提供的显式几何约束,从而增强了模型对三维场景的整体理解。
Omni-View在场景理解、空间理解与新视角生成任务上取得了较大的性能提升。
- 3D场景理解
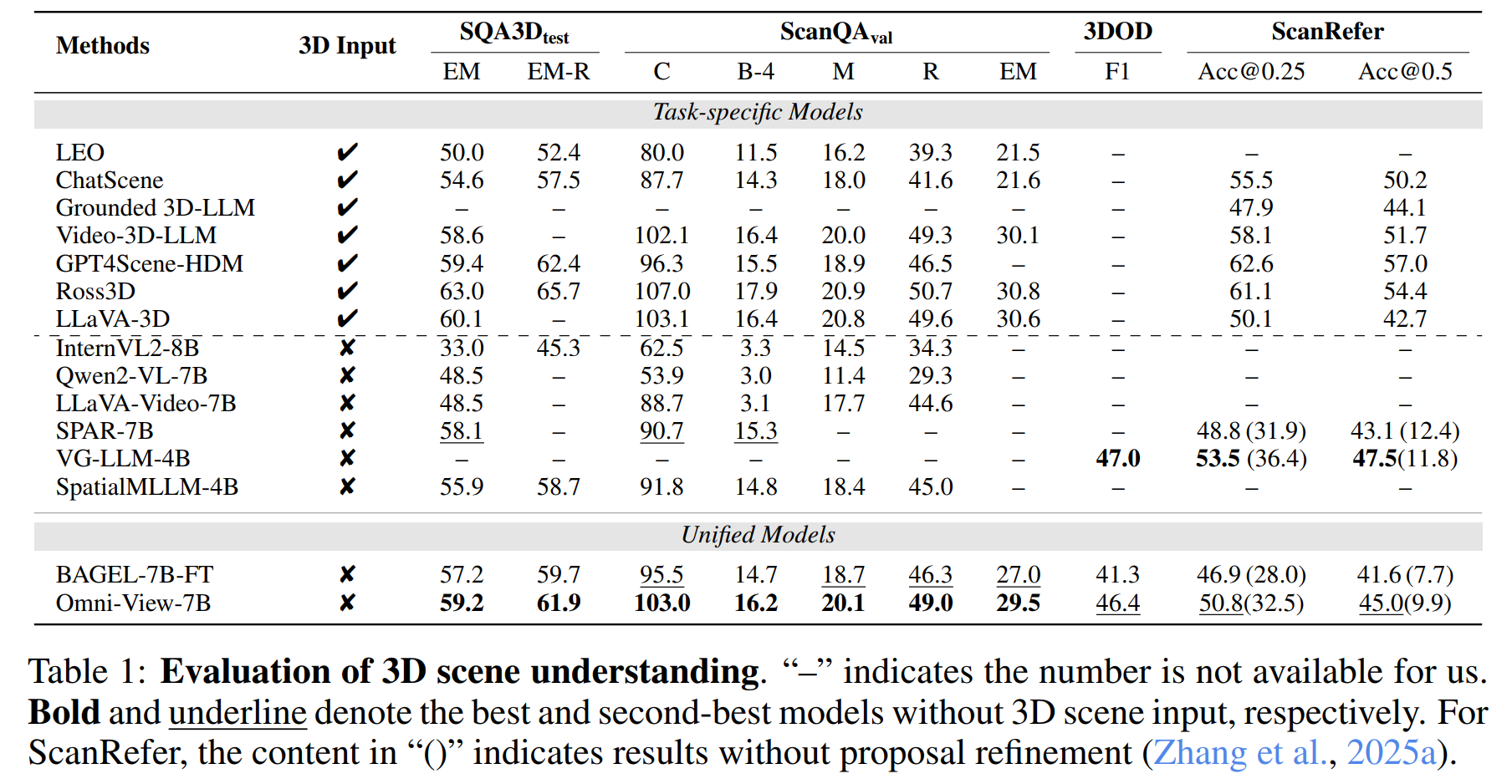
(1)我们的 Omni-View 方法优于所有目前不依赖 3D 场景输入的 MLLM 方法。
(2)性能的提升主要归功于我们提出的架构设计和训练方案。
(3)我们的方法在 QA 任务中的有效性与需要 3D 场景输入的先进 MLLM 方法相当。
- 空间推理
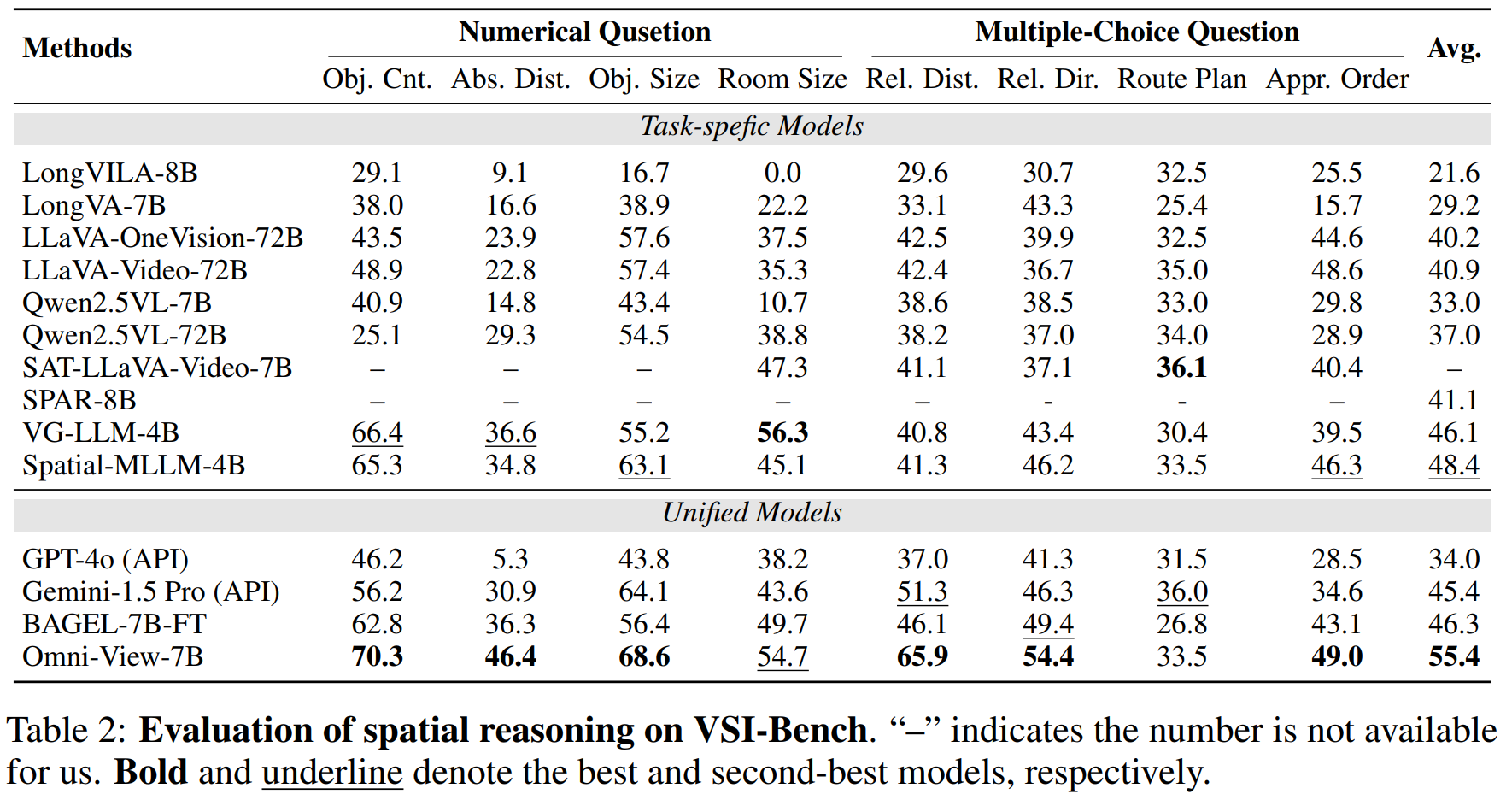
空间推理任务的结果更充分地证明了 Omni-View 在分析空间对象的相对或绝对位置和方向方面比以前的方法有所改进。
- 新视角生成
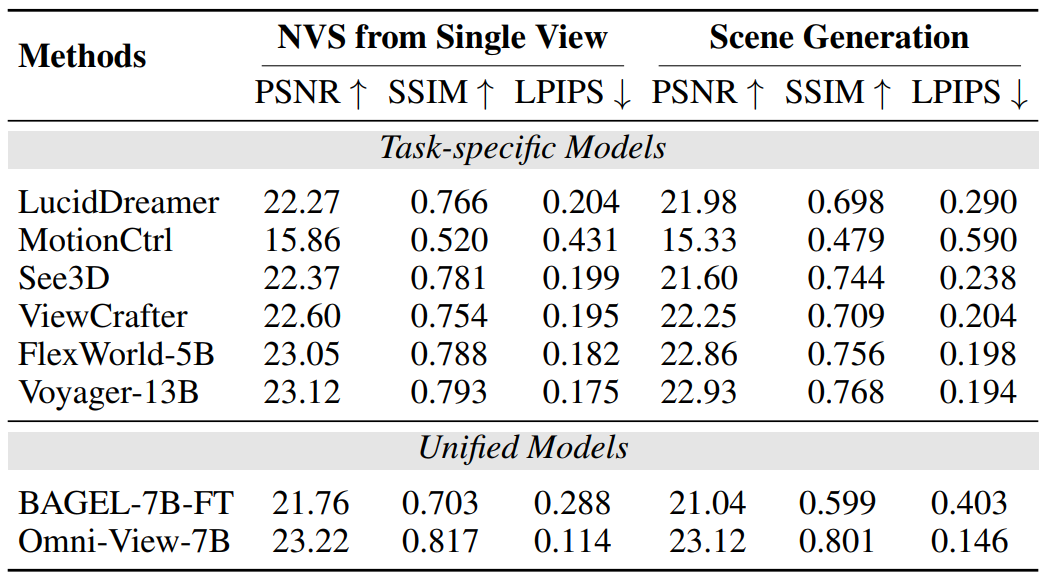
Omni-View 取得了最高的 PSNR 和 SSIM 值,以及最低的 LPIPS 得分,表明其图像质量可能优于其他方法。然而,在像素级保真度方面,Omni-View 相较于常用的场景生成模型仅有轻微的改进。
该论文第一作者为MILab博士生胡珈魁,卢闫晔助理教授为本文的通讯作者。该研究得到了国家重点研发计划、国家自然科学基金、北京大学肿瘤医院学科交叉专项资金的支持。
文章链接:Arxiv
代码链接:Github
添加评论