近期,MILab在潦草标注弱监督语义分割(Scribble-based weakly supervised semantic segmentation)领域取得进展,相关论文 "Scribble hides class: Promoting scribble-based weakly-supervised semantic segmentation with its class label" 发表在人工智能领域顶会AAAI 2024上。
语义分割(Semantic Segmentation)是计算机视觉中的一个任务,其目标是将图像中的每个像素分类到预定义的语义类别中,即要求对图像中的每个像素进行分类,以识别图像中不同对象的位置及其边界。然而,收集和手动标注这样数据集的过程既费力又耗时,这一挑战阻碍了语义分割在实际生产中的应用。利用稀疏标签的弱监督语义分割方法已经成为克服这一挑战的一个关键技术方向。这些方法使用图像级别、潦草涂鸦级别或方框级别的标注作为监督来训练语义分割模型。其中,图像级标注只提供了图像的类别标签,为模型提供的监督信号十分有限;方框级标注在多个物体距离很近的情况下会出现严重的目标重叠问题,这为模型的训练引入了很大的噪声。相比以上两种标注方式,潦草涂鸦级别的标注在监督信号的准确性和方便程度上达到了最佳的平衡,因此基于潦草涂鸦级别标注的语义分割方法成为近年来收到了广泛的关注,其应用前景十分广阔。
当前方法大致可以分为三类:基于正则化损失函数的方法,基于一致性学习的方法,以及基于局部扩散的方法。基于正则化损失函数的方法在于设计正则化损失函数,从而防止网络在训练时产生过拟合的现象;基于一致性损失函数的方法旨在利用自监督学习的策略使网络能够学习到图像中的不变特征。这两种方法虽然能够提升网络的鲁棒性和泛化性,但并没有解决网络难以获取足够监督信号的问题。相比之下,基于局部扩散的方法通过设计扩散算法,例如图和超像素等,将像素级标注从涂鸦扩散至全图来生成伪标签,从而利用伪标签对模型进行训练。伪标签虽然能够提供足够的监督信号,但当前基于局部扩散方法生成的伪标签并不够准确,这是因为扩散过程只需要对涂鸦标签进行局部建模,而不是对图像进行全局建模,从而导致扩散得到的伪标签只能局限于涂鸦标签附近。使用这样的伪标签来训练会导致分割网络缺乏对全局语义信息的理解。
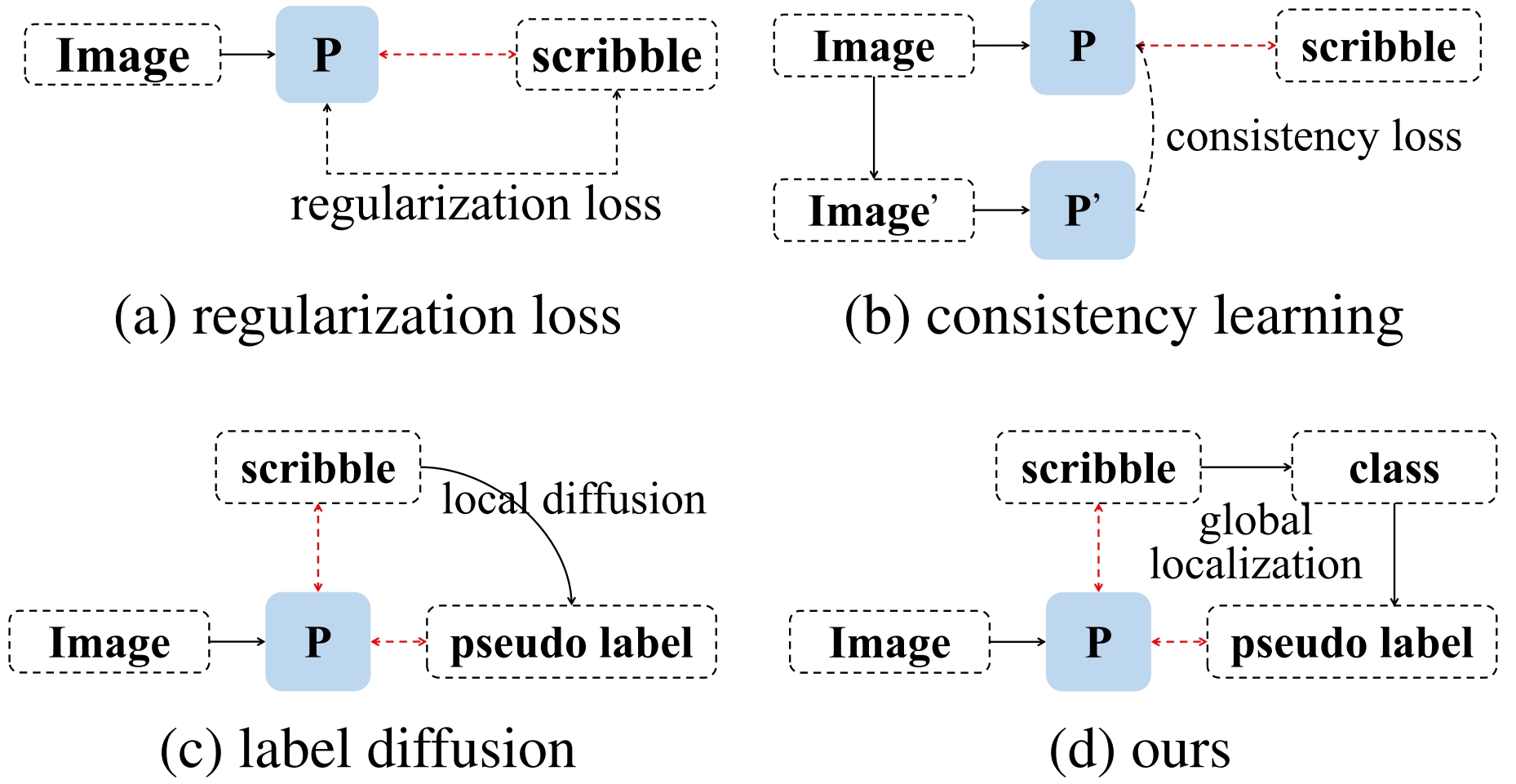
图1. 基于不同训练策略的弱监督语义分割方法对比
基于以上背景,MILab提出了一种融合全局类别信息的潦草标注语义分割方法,其利用潦草涂鸦标签中隐含的类别标签训练图像级语义分割网络从而得到包含全局信息的伪标签,而后用该伪标签与潦草涂鸦级标注联合监督训练一个语义分割网络。然而由于伪标签是由类别标签训练获得,包含了大量噪声导致前景信息分割不准确,针对这一问题,本文提出了一个局部纠正模块(Localization Rectifcation Module)用于修正语义分割模型最后一层特征图中物体边缘对应的部分。此外,本文还提出了一个距离熵损失函数(Distance entropy),用于减少伪标签边缘部分的不确定性,同时增加涂鸦标签附近的确定性,进而提升模型的鲁棒性和准确性。
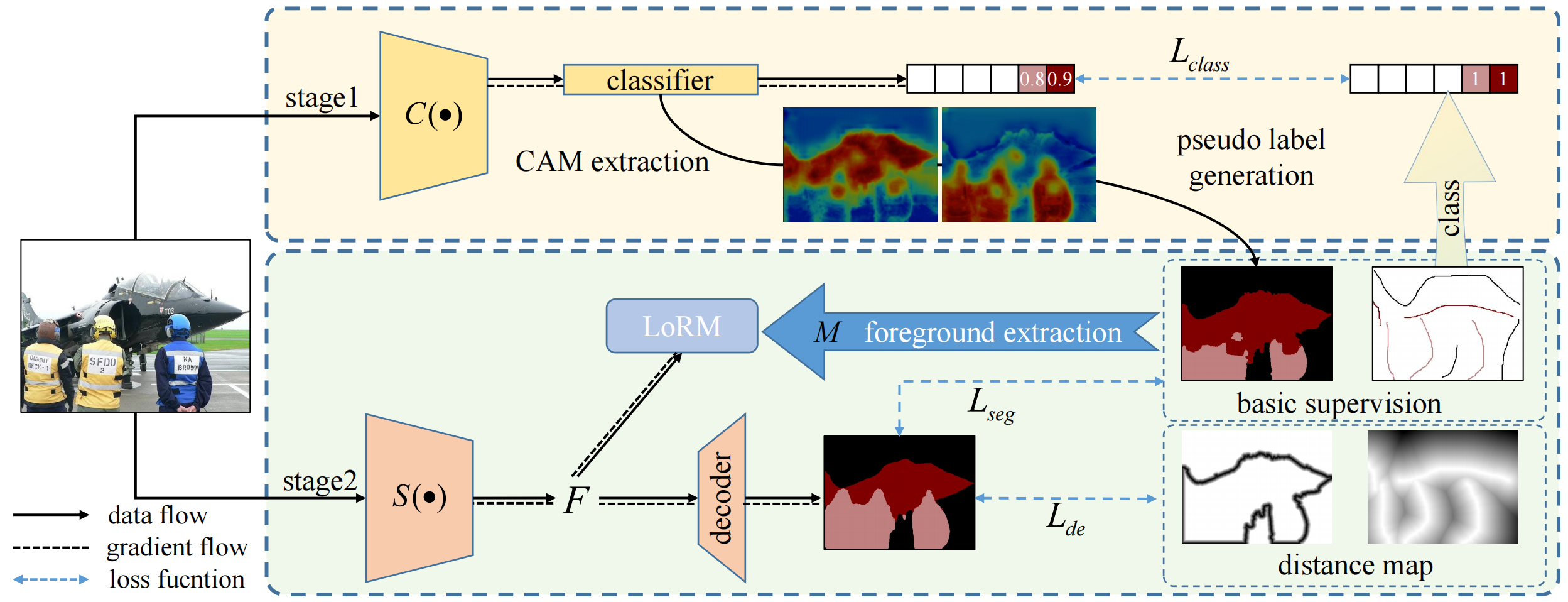
图2. 本文提出的一种融合全局类别信息的潦草标注语义分割方法结构图
研究团队在涂鸦标注领域的标杆数据集ScribbleSup上进行了实验,实验结果证明,本文提出的方法不仅在分割精度上达到了先进水平,同时在鲁棒性和稳定性方面也显著优于领域内的同类方法。
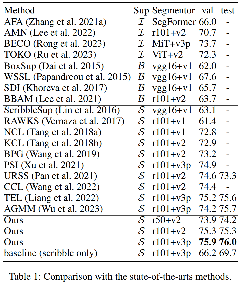
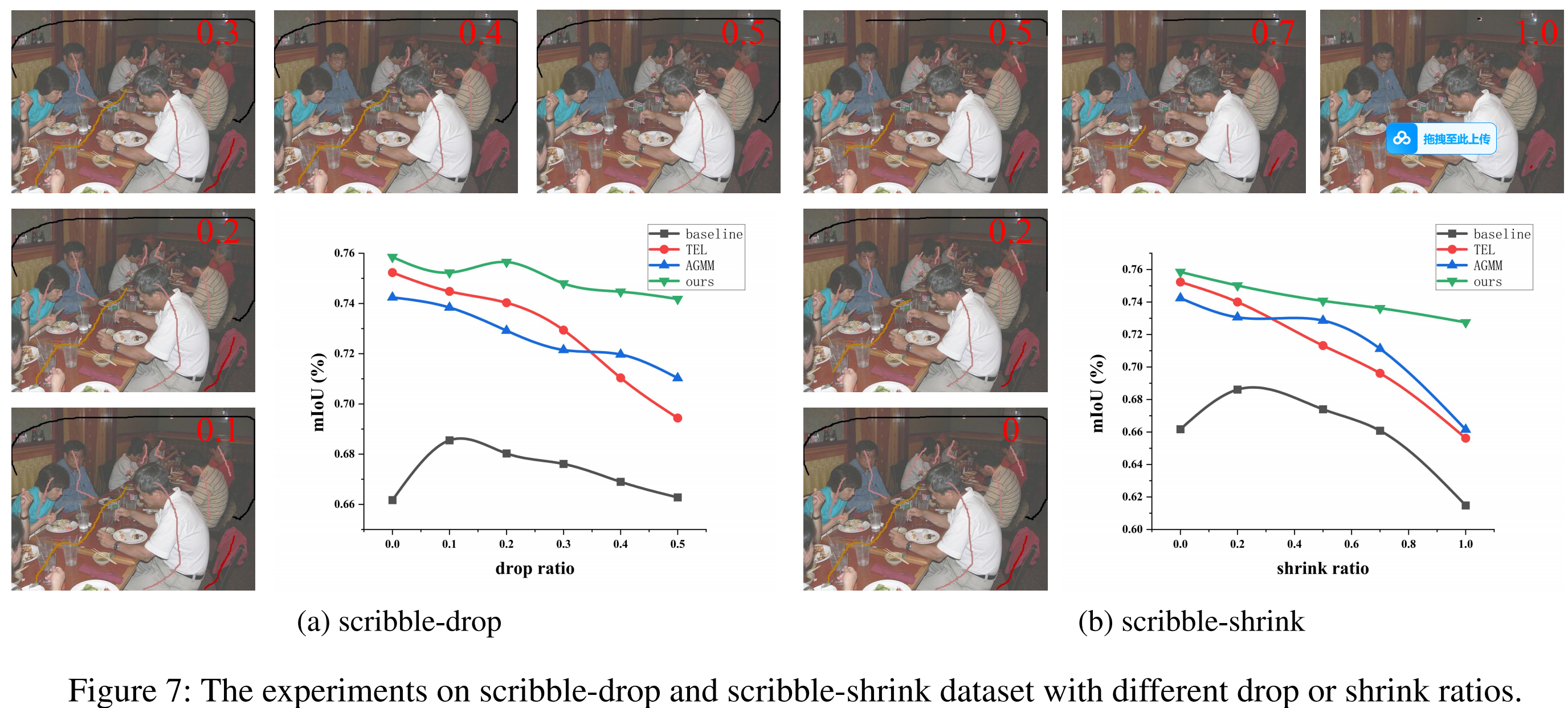
图3. 本文提出的方法在ScribbleSup数据集上的准确度(左)和在不同程度scribble退化下的准确度(右)
该论文由MILab课题组访问学生张心亮和MILab博士生朱磊共同一作,卢闫晔助理教授为本文的通讯作者。其他合作者还包括博士生何航舟和金录嘉。该研究得到了国家自然科学基金等项目的经费支持。
文章链接:https://doi.org/10.1609/aaai.v38i7.28563
代码链接:Code
添加评论