近期,MILab在可解释医学图像分类模型方面取得进展,提出了一种无需微调的可解释分类模型域自适应方法 ,相关研究论文“Training-free Test-time Improvement for Explainable Medical Image Classification”已被MICCAI 2025会议接收。
深度学习技术在医学图像分析中发展迅速,然而模型的可解释性与准确性之间长期存在权衡,限制了其在临床场景的广泛应用。概念瓶颈模型(CBM)通过预测可解释的概念并基于这些概念进行分类,在保持可解释性的同时实现了与黑箱模型相当的性能,已被广泛应用于皮肤疾病、白细胞分类等多个医学图像分类任务。
但当 CBM 部署到新环境时,由于医学成像设备、机构、和病人群体等的不同,获取的影像数据的特征会表现出极大的偏移,从而导致 CBM 的概念预测。虽然微调、以及一些现有的测试时适应(TTA)方法可以仅通过图像级分类标签提升模型在域外数据上的性能,但是它们无法有效保留 CBM 概念预测的可解释性和可靠性,而在新数据上获取医学领域专家注释的概念标签成本高昂。

针对上述问题,研究团队提出了一种无需训练的混淆概念识别策略。该方法仅需利用最少的新数据(如每类 4 张图像)和图像级标签,通过以下两个关键操作提升域外性能,同时不牺牲源域准确性:
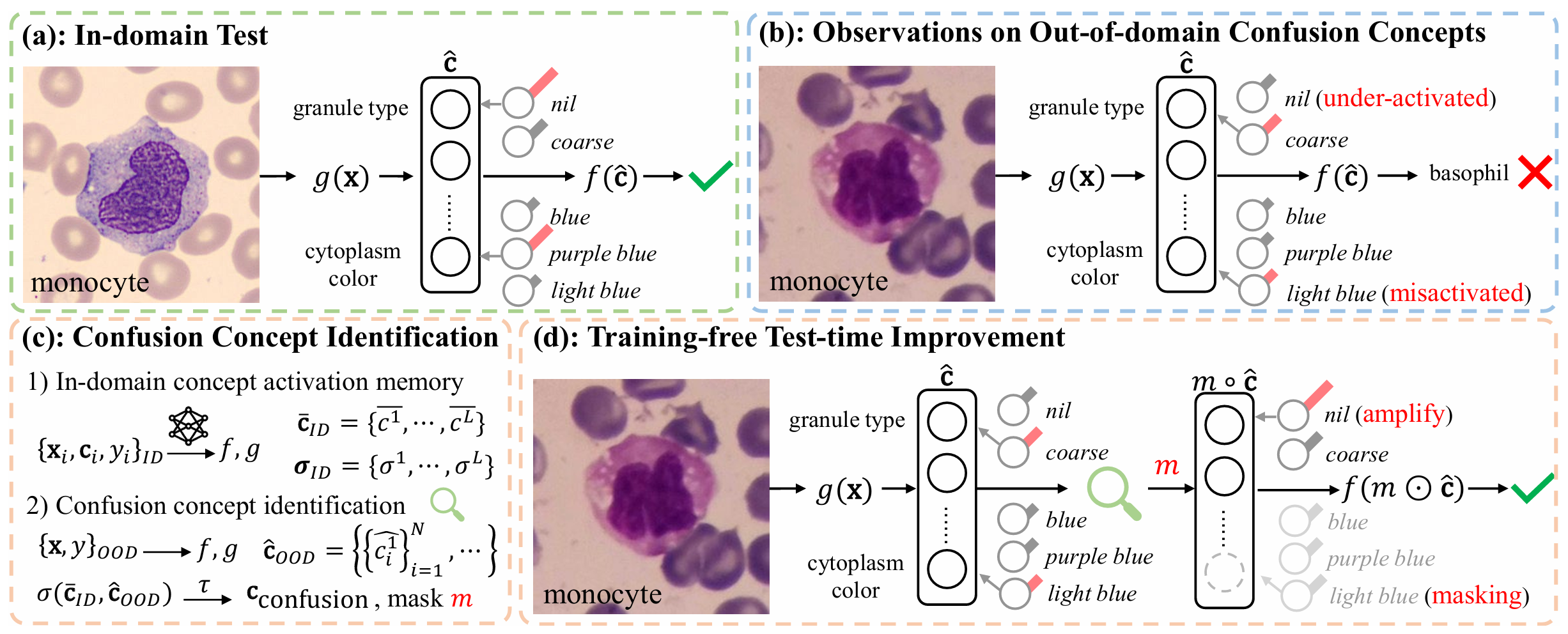
实验在皮肤图像和白细胞图像两个医学图像分类任务上进行验证,结果表明:
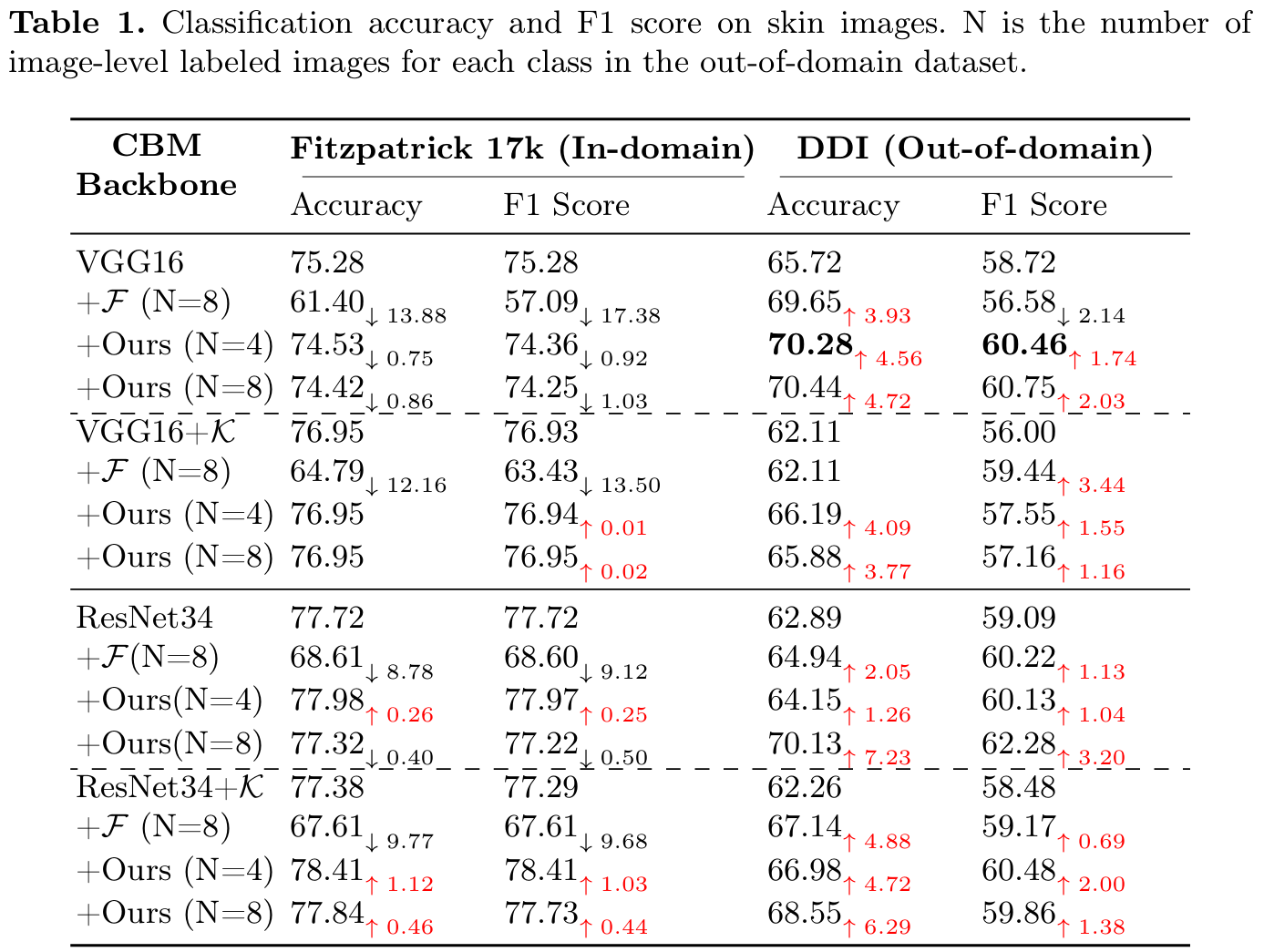
- 性能提升显著:在皮肤图像数据集上,使用 VGG16 作为骨干网络,仅用每类 4 张目标域图像,该方法使域外数据集(DDI)的准确率提升 4.56,F1 分数提升 1.74,超过了使用两倍数据量进行微调的效果;在白细胞图像分类中,面对染色条件和成像设备差异导致的域偏移,方法同样有效提升了模型在 Scirep 和 RaabinWBC 等域外数据集上的性能。
- 源域性能保持:与微调可能导致源域性能大幅下降不同,该方法在几乎所有实验设置下均能保持甚至提升模型的源域性能。例如,在白细胞分类任务中,微调导致源域准确率从 99.77 降至 62.96,而该方法则维持了源域的高准确率。
- 模型可信度验证:通过可视化推理过程和 Grad - CAM 技术分析表明,该方法使模型在推理时更专注于目标对象,不仅提升了分类准确率,还增强了模型的可信度。

该论文第一作者为MILab博士生何航舟和本科生唐佳晨,卢闫晔助理教授为本文的通讯作者。其他合作者还包括MILab博士后朱磊和博士生李凯文。该研究得到了国家自然科学基金等项目的经费支持。
文章链接:[2506.18070] Training-free Test-time Improvement for Explainable Medical Image Classification
添加评论